AI agents invade observability: snake oil or the future of SRE?
The Mooster and friends would like to join your ops team.
This newsletter was started 5 years ago to explore emerging observability and monitoring startups. In the most boring sense, these companies take operational data and create insights from that data for humans. This always involves a lot of dashboards, alerts, API integrations, and a large monthly bill.
The businesses sometimes take off—Cribl has raised $600 million dollars since first mentioned in 2019—and sometimes the technology takes a while to reach maturity (looking at you, eBPF). There’s also the standard IT hype cycle and new use cases for monitoring, like developers building applications using large language models or quasi-trends like data observability. In general: logs, metrics, traces and events go in, useful information for a developer or operator should come out.
As of fall 2024, a growing number of people and large software companies believe this model is about to fundamentally change with advances in AI. This issue of Monitoring Monitoring is about what that could look like for the observability business… if “agentic” generative AI lives up to the hype.
Agents everywhere (even CRM isn’t safe)
The next wave of gen AI is all about agents, and not at all in the “server monitoring agent” or “instrumentation agent” sense (like Dynatrace OneAgent).
This new agent (or “agentic”) focus refers to large language models (LLM) that can take actions using real world data with human approval. The latest models from OpenAI, for example, do a great job of solving very complicated programming, math, and science problems using advanced reasoning. But ChatGPT can’t do things like use notes from sales calls and internal customer data to negotiate and close a contract… yet?
A quote from Marc Benioff is useful context at this point, minus his digressions on esoteric Japanese philosophy: “we have to pivot the whole company to agents” he recently told Fortune. (The massive Salesforce conference in San Francisco, Dreamforce, has now been renamed Agentforce.)
Compared to CRM and fintech, monitoring companies are just starting to arrive at the agentic AI party. The big question: what happens if agentic AI becomes as good as a junior operator or developer at understanding operational data, including connections between different signals and systems?
Meet the newest member of your ops team
There are many startups emerging in the agentic monitoring space, all of which have capabilities that go beyond the chat interfaces that have been released by major vendors to date. Very broadly, they fall into the following categories:
DevOps and/or incident response agents trying to automate away parts of on-call or routine maintenance. The bots you can choose from include Kura (from Kura), OneGrep Bot (from OneGrep) and The Mooster (from Wildmoose). Beeps is also in this space but seems to be pre-launch (and have not revealed a bot name)
“Platforms of agents” or agent toolkits to increase automation. RunWhen has built a solution around agents that can automate multiple types of engineering tasks, and Acorn Labs has developed an open-source toolkit to build generic agents of any type.
Expert site reliability engineer (SRE) agents with domain specific knowledge of cloud or Kubernetes. Parity and Cleric position themselves in this area, although the line between SRE-focused and DevOps agents is blurry. There’s also the open-source project k8sgpt.

The marketing for all of these solutions is about doing more with less, and in some cases moving away from the “co-pilot” or “assistant” language towards something more embodied: Parity and Cleric position their solutions as an actual SRE who joins your team: “We’re building an operator, not another tool.”
More AI snake oil, or something else?
This isn’t the first AI hype cycle in the monitoring space. The various features sold in the past 5-7 years as AIOps, from the practitioner standpoint, were (at best) a mixed success. The machine learning algorithms of the 2010s did not fundamentally change the on-call or incident response workflow. Advanced anomaly detection is helpful but it tends to get turned off (or removed from the day-to-day) if false positives repeatedly wake people up at 3am.
Venture capitalists think this time might be different. a16z, writing about the CRM industry, laid out what it thinks are the platform components of a Salesforce-killer:
[T]he core of the next sales platform could be entirely unstructured and multimodal, including text, image, voice, and video. A company’s sales platform could include data about existing and prospective customers from countless sources… Furthermore, the LLM powering the platform would be constantly ingesting data to create the most up-to-date context.
If we replace “voice and video” (fortunately not a key part of the job in SRE) with “operational data”, ticketing systems, on-call runbooks, documentation, and source control—you get a marketecture that looks identical to the solutions many of these startups are building.
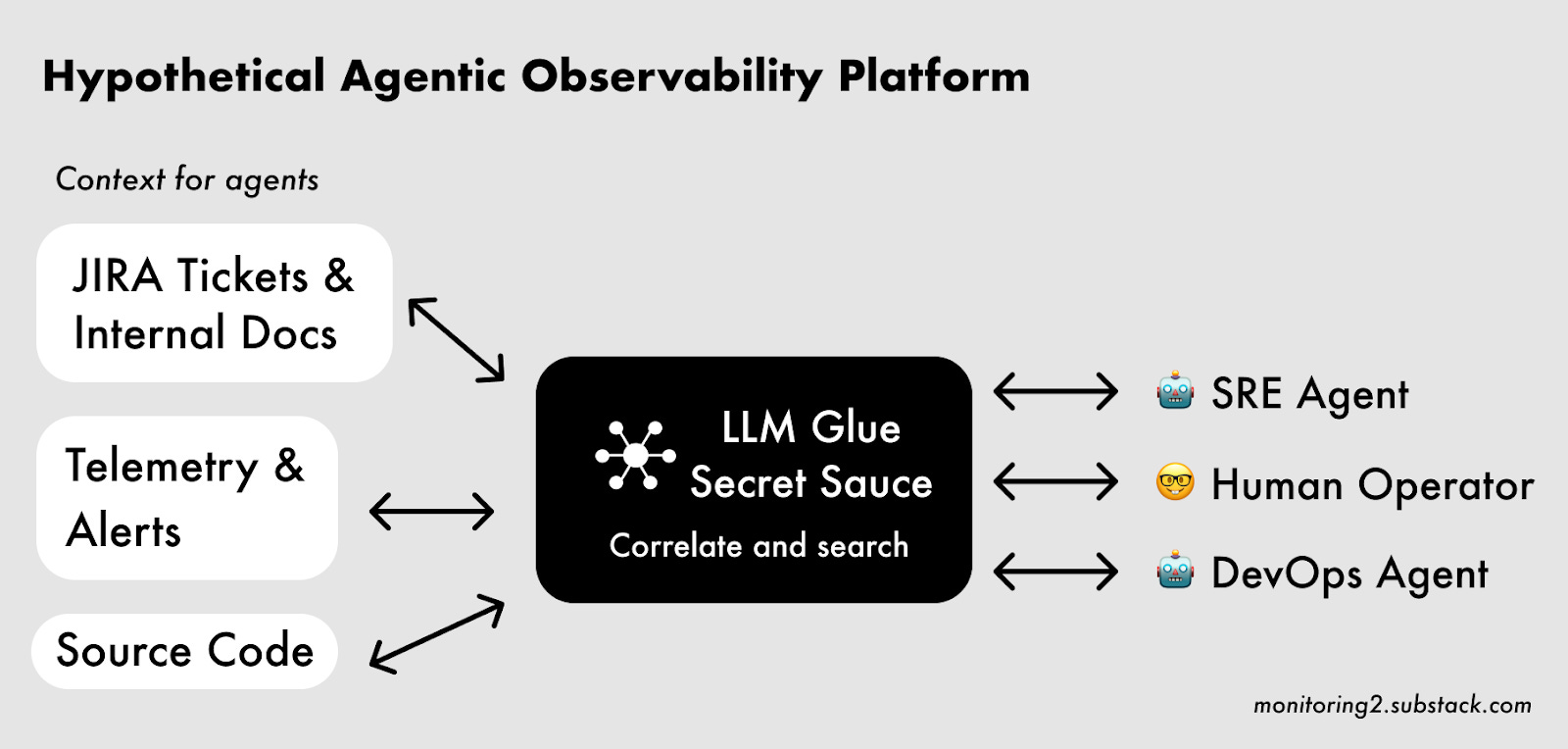
This is different from the 2010s historical model of monitoring startups that started by creating a new type of database inspired by an internal system learned at a large technology company. Instead of web scale, the secret sauce is connecting many more sources of real time, operational, and internal data that are brought together via proprietary LLM glue.
That’s the concept at least, and if it works it would change the way practitioners do observability, monitoring and incident response.
Benchmarks and murder mysteries
If every major APM vendor and dozens of startups release agents in the next year, it will be difficult for customers to tell what’s snake oil or what’s actually useful. One approach, also seen in the financial space, is having open benchmarks for assessing how well agents can answer questions and show domain-specific knowledge.
In the past week, Parity released the first known benchmark for Kubernetes or cloud called SREBench—you race their agent in a simulated cluster to see who can diagnose the root cause faster. They built the benchmark, according to their blog post, by integrating concepts from the closest existing benchmark they found that could be applied to modern-day SRE: solving murder mysteries.
While there are many different types of AI benchmarks available, more domain-specific ones for operational and incident response tasks are welcome and needed. Benchmarks are far from perfect, but could help future customers of agents have a starting point for measuring how effective an agent is at solving problems in a simulated environment. Otherwise, like the previous AIOps wave, we’re relying mostly on analyst reports and white papers provided by eager sales teams on how much your mean time to resolution (MTTR) will decrease.
Dollar signs and dilemmas
We’re in the very early days of understanding the impact of LLM-based agents on the observability space. Besides the questions around how effective these agents will be in complex operational environments, there’s an equal number of data privacy and regulatory questions that have yet to be resolved. Are you (or EU regulators) willing to give The Mooster your transaction logs with potential PII data? There’s also the open question of how to, well, monitor these agents for compliance and safety.
Pricing is another concern. If effective SRE agents require large amounts of operational data and lots of NVIDIA GPUs to do their job: add a few more zeros to the bill from your favorite APM vendor.
If you’re a venture capitalist, you see dollar signs. If you work in the monitoring space, you might see the end of your job. If you’re a customer of an monitoring vendor, you’re probably just tired of hearing about AI.
As it’s Agentforce in San Francisco this week, last word goes to Benioff from his Fortune interview.
“It is about driving through the innovator’s dilemma.”
🚗🚗🚗
Subscribe to the newsletter for updates to see how this evolves in the next few months.
If you read this thinking it was going to be about LLM monitoring, check out this post from early 2023: Large Language Model Observability.
Disclosure: Opinions strictly my own and not my employers. I am not a consultant, employed, or an investor in any of the companies mentioned. There are no paid placements, sponsorships, or advertisements in this newsletter.