
Observability Pipelines at Kubecon
I learned about a new type of marketecture, and have a feeling it’s not going away anytime soon. It’s called the observability pipeline.
The term appears multiple times on the marketing pages of companies who exhibited in the start-up tier at Kubecon last week. This tier is the lowest-cost sponsorship and thought it’d be an interesting filter to learn about new (or thrifty) software companies. Out of the 74 startup exhibitors:
10 sell something involving data or storage
8 sell something involving security
12 sell something involving Kubernetes cluster management, especially multi-cluster
11 sell something that could be described as a monitoring or observability solution
Until recently, monitoring businesses could be categorized by the type of operational data their software collects: logs (Splunk) or metrics and traces (APM companies). This categorization still kind of works in late 2019:

A new category of monitoring startups, however, is companies that offer some kind of observability pipeline, an event-driven workflow for filtering and routing operational data. Think of it as intelligent software glue for teams with dozens of tools and services that deal with operational data, visualization and alerts.
The architecture of these pipelines can be found on the Cribl, Sensu, and NexClipper websites. You also see a similar concept without an ops-specific focus in Amazon’s EventBridge or Azure’s Event Grid. There’s also Stripe’s open-source Veneur. Everybody visualizes it in a similar way—data in, magic, data out:

A generic version of it could look something like this:
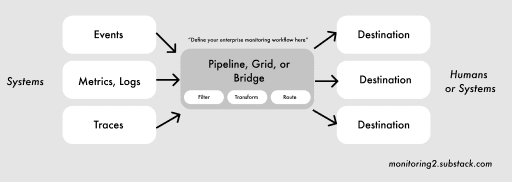
Implementing a monitoring pipeline opens up some interesting possibilities. A major use case is simplifying operational concerns around compliance and security while giving individual engineering or ops teams autonomy to extend the pipeline for different workflows, dashboards, analytics, and alerting without breaking things for others.
For example, imagine an ops team wants to have the capability to detect anomalies that could indicate “something very bad is happening” using bleeding-edge machine learning (ML). With a pipeline defined, they just have to make a change to an existing configuration and logs for specific apps are automatically re-routed a third-party service that specializes in ML (like Zebrium, another Kubecon exhibitor). If the data needs to be sanitized before sending off to the third-party, no problem: the team just attaches a new rule that removes PII data. There’s a lot of flexibility, including picking and choosing specialized tools to visualize and understand data.
Cribl, founded by ex-Splunk employees, also points out on their site that there’s potential for cost savings: you can implement policies in the pipeline so you see the most important data in real-time or convert logs into cheaper metrics. It’s still early, but emerging standards (see OpenMetrics, OpenTelemetry) could make integrating more data into pipelines easier as well.
Event-driven pipelines are not a new idea at all, but as far as I can tell it’s new to see pipelines as a distinct and highly configurable feature bundled inside of monitoring solution. If you squint, it almost looks like the beginning of control and data planes for observability.
Kubecon startups not doing pipeline stuff are equally interesting:
Humio, fresh off a Thoughtworks Tech Radar mention, and Chronosphere, a few weeks post-series A. Both seem to be building their products/special sauce around custom time series databases.
Many founders of observability startups over the past few years can describe themselves as “ex-[large technology company]”. Flowmill is what happens when the founder is a Computer Science PhD from MIT’s CSAIL Lab and is an expert on some pretty interesting and bleeding-edge Linux kernel technology (eBPF).
Rookout seems seems incredibly cool from a developer perspective: click on a line of your code and get live production logs or metrics. They call it non-breaking breakpoints, and the demo on their homepage is impressive.
There’s a lot of really interesting stuff going on and want to get into the details of BPF and why it’s so fascinating in a monitoring context in the next newsletter.
Happy Thanksgiving this week for people based in the US. This post on using a bakery for explaining technology jobs to family comes in handy this time of year.
Thanks for subscribing, and if you enjoyed this feel free to share with the link below.
Newsletter disclosure: Opinions my own. I am not employed, consulting, or an investor in any of the mentioned companies or their competitors.